
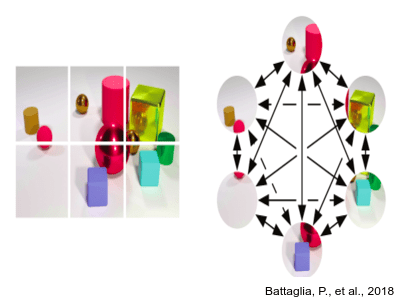
The laboratory endeavors to discover data-driven inference by developing artificial intelligence methods, particularly deep learning, graph neural networks (GNNs), and reinforcement learning (RL). Currently, these domains have shown promising performance in a diverse set of applications. Our mission is to enrich the theoretical building blocks and simultaneously exploring their applications within drug discovery and bioinformatics, computer vision, knowledge graphs, physical science, and robotics.
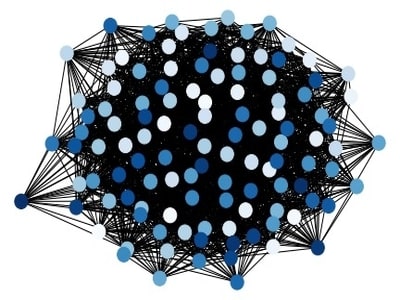
GNNs, for instance, have received increasing attention due to their superior performance in many node and graph classification/regression tasks. GNNs are neural networks that take graphs as inputs. These models operate on the relational information of data to produce insights not possible in other neural network architectures and algorithms.
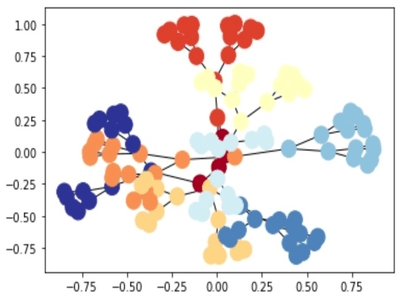
Graphs are a ubiquitous data structure and a universal language for describing complex systems. In the most general view, a graph is simply a collection of objects (i.e., nodes), along with a set of interactions (i.e., edges) between pairs of these objects. For example, to encode a social network as a graph we might use nodes to represent individuals and use edges to represent that two individuals are friends. In the biological domain, we could use the nodes in a graph to represent proteins, and use the edges to represent various biological interactions.
The power of graph formalism lies both in its focus on relationships between points (rather than the properties of individual points) as well as in its generality.


Medizinische Universität Graz

Polytechnic University of Milan
Hossein Hajiabolhassan, Zahra Taheri, Ali Hojatnia, and Yavar Taheri Yeganeh
Journal of Chemical Information and Modeling (2023)
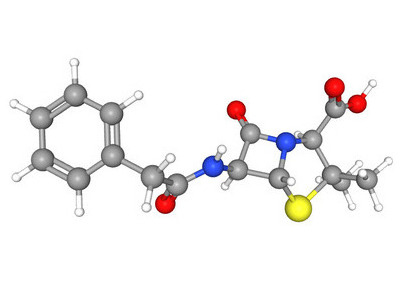
Abstract: To accurately predict molecular properties, it is important to learn expressive molecular representations. Graph neural networks (GNNs) have made significant advances in this area, but they often face limitations like neighbors-explosion, under-reaching, oversmoothing, and oversquashing. Additionally, GNNs tend to have high computational costs due to their large number of parameters. These limitations emerge or increase when dealing with larger graphs or deeper GNN models. One potential solution is to simplify the molecular graph into a smaller, richer, and more informative one that is easier to train GNNs. Our proposed molecular graph coarsening framework called FunQG, uses Functional groups as building blocks to determine a molecule’s properties, based on a graph-theoretic concept called Quotient Graph. We show through experiments that the resulting informative graphs are much smaller than the original molecular graphs and are thus more suitable for training GNNs. We apply FunQG to popular molecular property prediction benchmarks and compare the performance of popular baseline GNNs on the resulting data sets to that of state-of-the-art baselines on the original data sets. Our experiments demonstrate that FunQG yields notable results on various data sets while dramatically reducing the number of parameters and computational costs. By utilizing functional groups, we can achieve an interpretable framework that indicates their significant role in determining the properties of molecular quotient graphs. Consequently, FunQG is a straightforward, computationally efficient, and generalizable solution for addressing the molecular representation learning problem.
Show Abstract
Thomas Michel, Hossein Hajiabolhassan, and Ronald Ortner
Transactions on Machine Learning Research (2023)
Abstract: This paper considers the objective of satisficing in multi-armed bandit problems. Instead of aiming to find an optimal arm, the learner is content with an arm whose reward is above a given satisfaction level. We provide algorithms and analysis for the realizable case when such a satisficing arm exists as well as for the general case when this may not be the case. Introducing the notion of satisficing regret, our main result shows that in the general case it is possible to obtain constant satisficing regret when there is a satisficing arm (thereby correcting a contrary claim in the literature), while standard logarithmic regret bounds can be re-established otherwise. Experiments illustrate that our algorithm is not only superior to standard algorithms in the satisficing setting, but also works well in the classic bandit setting.
Show Abstract
Hossein Hajiabolhassan and Ronald Ortner
Sixteenth European Workshop on Reinforcement Learning (2023)
Abstract: We consider general reinforcement learning under the average reward criterion in Markov decision processes (MDPs) when the learner's goal is not to learn an optimal policy but accepts any policy whose average reward is above a certain given satisfaction level~σ. We show that with this more modest objective it is possible to have algorithms that only have constant regret with respect to the level~σ, provided that there is a policy above this level. This result generalizes findings of Bubeck et al. (COLT 2013) from the bandit setting to MDPs. Further, we present a more general algorithm that achieves the best of both worlds: If the optimal policy has average reward above this algorithm has bounded regret with respect to~σ. On the other hand, if all policies are below then we can show logarithmic bounds on the expected regret with respect to the optimal policy.
Show Abstract












